Conference Paper

2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
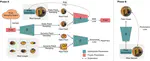
We introduce a hybrid feature representation using the anchor image to bridge the latent space of HumanGen with the existing 2D generator. We then adopt a pronged design to disentangle the generation of geometry and appearance.
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
In this paper, we propose Instant-NVR, a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera.
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
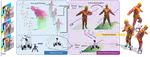
We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of ∼71M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects.
2021 International Joint Conference on Artificial Intelligence.
We propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs

2021 IEEE International Conference on Computational Photography.
We propose a novel scheme to generate opacity radiance fields with a convolutional neural renderer for fuzzy objects with high feaqurncy details.
2021 IEEE/CVF International Conference on Computer Vision.
We introduce GNeRF, a framework to marry Generative Adversarial Networks (GAN) with Neural Radiance Field (NeRF) reconstruction for the complex scenarios with unknown and even randomly initialized camera poses.