Abstract
Photo-realistic modeling and rendering of fuzzy objects with complex opacity are critical for numerous immersive VR/AR applications, but it suffers from strong view-dependent brightness, color. In this paper, we propose a novel scheme to generate opacity radiance fields with a convolutional neural renderer for fuzzy objects, which is the first to combine both explicit opacity supervision and convolutional mechanism into the neural radiance field framework so as to enable high-quality appearance and global consistent alpha mattes generation in arbitrary novel views. More specifically, we propose an efficient sampling strategy along with both the camera rays and image plane, which enables efficient radiance field sampling and learning in a patch-wise manner, as well as a novel volumetric feature integration scheme that generates per-patch hybrid feature embeddings to reconstruct the view-consistent fine-detailed appearance and opacity output. We further adopt a patch-wise adversarial training scheme to preserve both high-frequency appearance and opacity details in a self-supervised framework. We also introduce an effective multi-view image capture system to capture high-quality color and alpha maps for challenging fuzzy objects. Extensive experiments on existing and our new challenging fuzzy object dataset demonstrate that our method achieves photo-realistic, globally consistent, and fined detailed appearance and opacity free-viewpoint rendering for various fuzzy objects.

Overview
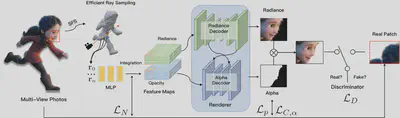
Given multi-view RGBA images, we use an SFS to infer proxy geometric for Efficient Ray Sampling. For each sample point in the volume space, the position and direction are feeding to an MLP based feature prediction network to represent the object at a global level. We next concatenate nearby rays into local feature patches and decoded them into RGB and matte with the convolutional volume renderer. An adversarial training strategy is used on the final output to encourage fine surface details. In the reference period, we render the entire image at once rather than per patch rendering.
Our Results
Acknowledgements
This work was supported by NSFC programs (61976138, 61977047), the National Key Research and Development Program (2018YFB2100500), STCSM (2015F0203-000-06) and SHMEC (2019-01-07-00-01-E00003).
Citation
@INPROCEEDINGS {9466273,
author = {H. Luo and A. Chen and Q. Zhang and B. Pang and M. Wu and L. Xu and J. Yu},
booktitle = {2021 IEEE International Conference on Computational Photography (ICCP)},
title = {Convolutional Neural Opacity Radiance Fields},
year = {2021},
volume = {},
issn = {},
pages = {1-12},
keywords = {training;photography;telepresence;image color analysis;computational modeling;entertainment industry;image capture},
doi = {10.1109/ICCP51581.2021.9466273},
url = {https://doi.ieeecomputersociety.org/10.1109/ICCP51581.2021.9466273},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {may}
}
Haimin Luo
PhD Candidate
My research interests include Neural Modeling and Rendering, 3D Reconstruction, Motion Capture and Animation.